
きっかけ
先日Sさんと久々にクラフトビールを飲みながらいろいろ話した。
その際、「ハーフマラソン出場に向けて生成AIにトレーニングメニューを作ってもらい、レースまでに準備して無事完走した」という話を聞いた。
それいいなーと思い、自分も早速今年の目標2つ達成に向けてメニューを作ってもらった。
ちなみに今年の目標は以下の2つ。
- スパルタンレースのトライフェクタ達成
- Sprint・Super・Beastの3種を1年以内に完走すると手に入る称号で、5月の千葉Super、7月の静岡Sprint、9月の新潟Beastと3戦続く。
- HYROX初出場・初完走
- ランニングと筋力系ワークステーションを交互にこなすフィットネスレースで、スパルタンとはまた違う種類のキツさがある。
と、メニューができたのはいいが、日々の記録を手動でつけるのは結構面倒。
できるだけラクできないかと、そのまま生成AIに相談してみた。
(ランニングや筋トレの)実施結果をスプレッドシートで残し、さらに、それをBigQueryに取り込み、MCPサーバーで分析したりレポート作成をしたいです。
というところからぬるっとスタート。
前提
| 項目 | 内容 |
| スマートウォッチ | Garmin Forerunner 955 |
| GCP | アカウント有り |
| Claude | Plusプラン(claude.ai) |
| Claude Code | VS Codeで使用 |
| Anthropic API | ひとまず$5課金 |
| その他 | コードはほとんど書けない、いわゆる非エンジニア |
やりたいこと
- ランニングデータをなるべく手間なくスプレッドシートに記録したい
- 筋トレデータもスプレッドシートで管理したい
- 両方のデータをBigQueryに蓄積したい
- Claude CodeのMCPサーバー経由で自然言語で分析・レポートができるようにしたい
- TableauやLooker Studioでのビジュアライズにも使いたい
「入力の手間を最小化しつつ、分析・可視化に使えるデータ基盤を作る」という感じ。
全体構成
処理の流れはこう。
Garminアプリ(スクリーンショット) ← ランニングはここから手動スタート
↓ Claude Codeにアップロード → garmin_to_sheets.py実行
↓ Googleスプレッドシート(running_log / training_log) ← 筋トレはここから手動入力スタート
↓ GAS(Google Apps Script。毎日自動同期 or 手動で全行洗い替え)
↓ BigQuery(taiichirou_fitness データセット)
↓ Claude Code(MCPサーバー)で自然言語分析 / Tableau・Looker Studio
入力データは2種類。
ランニングデータはGarminアプリのスクリーンショットをClaude Codeにアップロードして自動追記。
筋トレデータはスプレッドシートに手動入力する。
どちらもGASで毎日BigQueryに自動送信(定期実行)される。
使用ツール:Garmin / Google スプレッドシート / Google Apps Script / BigQuery / Anthropic API(claude-haiku-4-5)/ VS Code / Claude Code / MCP
各パートの具体的な作業
Step 1:スプレッドシートの構成を作る
最初にClaudeと一緒にスプレッドシートの設計。
DBフォーマットで設計し、1行1レコードが原則。
BigQueryへの同期を前提にしているため、列名はすべてスネークケース(例:distance_km)で統一。
シートは6つ構成。
- training_log:筋トレ記録
- running_log:ランニング記録
- exercise_master:種目マスタ
- run_type_master:ランニング種別マスタ
- BQ_schema:BigQueryスキーマ管理
- ClaudeCode用プロンプト:よく使うプロンプトのストック
BigQueryに同期するのはtraining_logとrunning_logの2つのみ。
残りは基本的にスプレッドシート上での管理・参照用。
synced_at列を設けており、BigQueryへ送信済みの行には自動でタイムスタンプが記録される。
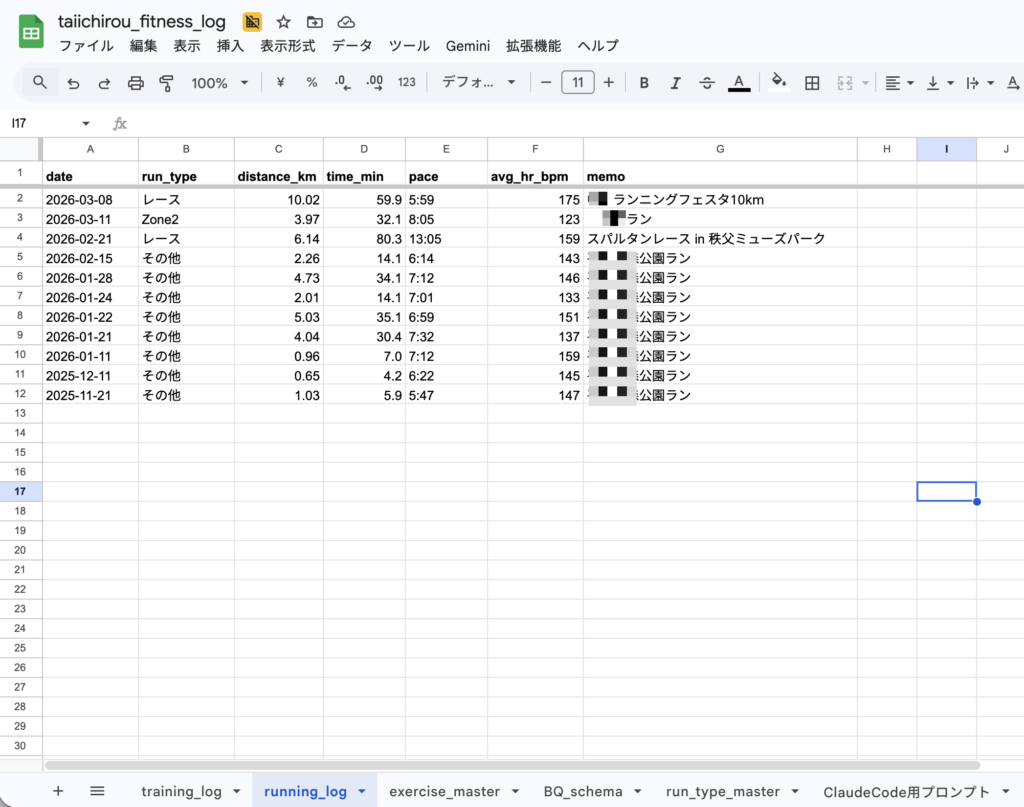
running_log のカラム構成
| カラム名 | 型 | モード | 内容 |
| date | DATE | REQUIRED | 記録日 |
| run_type | STRING | NULLABLE | ランニング種別(Zone2 / レースなど) |
| distance_km | FLOAT | REQUIRED | 距離(km) |
| time_min | FLOAT | NULLABLE | タイム(分) |
| pace | STRING | NULLABLE | ペース(例:8:05) |
| avg_hr_bpm | INTEGER | NULLABLE | 平均心拍数(bpm) |
| memo | STRING | NULLABLE | メモ |
| synced_at | TIMESTAMP | NULLABLE | BigQuery同期日時 |
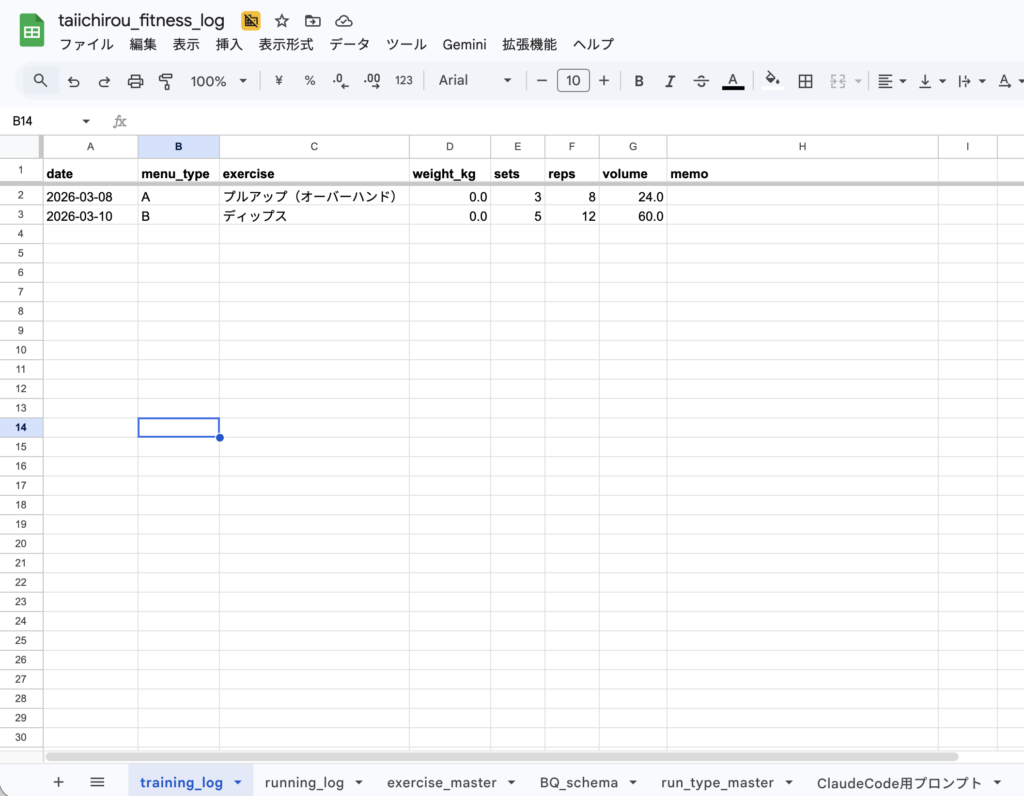
training_log のカラム構成
| カラム名 | 型 | モード | 内容 |
| date | DATE | REQUIRED | 記録日 |
| menu_type | STRING | NULLABLE | メニュー種別(A引く系 / B押す系+体幹など) |
| exercise | STRING | REQUIRED | 種目名 |
| weight_kg | FLOAT | NULLABLE | 重量(kg) |
| sets | INTEGER | REQUIRED | セット数 |
| reps | INTEGER | REQUIRED | レップ数 |
| volume | FLOAT | NULLABLE | ボリューム(重量×セット×レップ) |
| memo | STRING | NULLABLE | メモ |
| synced_at | TIMESTAMP | NULLABLE | BigQuery同期日時 |
実際のスプレッドシートはこんな感じ。(生成AIによるサンプルデータ含む)
Step 2:GCPプロジェクトとBigQueryの準備
GCPコンソール(console.cloud.google.com)で以下を順番に設定。
- GCPプロジェクトを新規作成(プロジェクトID:taiichirou-fitness)
- 「APIとサービス」から「BigQuery API」を有効化
- 同じく「Google Sheets API」も有効化(garmin_to_sheets.pyからスプレッドシートへ書き込むために必要)
- BigQueryにデータセットを作成(データセット名:taiichirou_fitness、リージョン:asia-northeast1)
- スキーマに従いテーブルを作成(running_log・training_log)
- サービスアカウントを作成してキーファイルを発行(BigQueryの必要権限を付与)
テーブルのスキーマは生成AIが作成してくれたJSONで定義した。
ここで、少々だけど、時間を食ってしまった(後述)。
Step 3:GASスクリプトの作成
スプレッドシートとBigQueryをつなぐGAS(Google Apps Script)を作成。
関数は2種類用意。
差分同期(syncToBigQuery)
毎晩0〜1時に自動実行。
synced_atが空の行=まだBigQueryに送っていない行だけを対象にして送信する。
送信後、その行のsynced_atに現在時刻を記録する。
全行洗い替え(fullSyncToBigQuery)
手動実行専用。
BigQueryのテーブルを一度削除して再作成し、スプレッドシートの全行を再投入する。
データを修正・削除したときや、誤ったデータをまとめて消したいときに使う。
GASの全体構成はこんな感じ。
syncToBigQuery() ← 毎晩自動実行(差分のみ)
fullSyncToBigQuery() ← 手動実行(全行洗い替え)
syncSheet() ← syncToBigQueryから呼ばれる内部関数
fullSyncSheet() ← fullSyncToBigQueryから呼ばれる内部関数
getSchema() ← テーブル再作成時のスキーマ定義を返す
差分同期だけだとスプレッドシートで行を削除してもBigQueryには残ったままになる。
それに気づいて全行洗い替え関数を後から追加した。(最初から入れておけばよかった)
Step 4:garmin_to_sheets.py の作成
ランニングデータの入力をラクにするためにPythonスクリプトを作成した。
運用の流れ。
- ランニング後、Garmin Connectアプリのアクティビティ画面をスクリーンショットで保存
- VS CodeのClaude Codeに画像をアップロードしてデータ入力を依頼
- Claude Codeがgarmin_to_sheets.pyを実行し、スプレッドシートのrunning_logに追記される
スクリプトの内部処理は以下。
- 画像をClaude API(claude-haiku-4-5)に送信
- Claude APIが画像から距離・タイム・ペース・平均心拍数を抽出
- 同じ日付のデータが既にスプレッドシートにないか重複チェック
- 問題なければGoogle Sheets APIでrunning_logシートに1行追記
これでランニング記録の追加がだいぶラクに。
週3くらいの作業とはいえ、面倒くさがり屋としてはこの仕組みができたことは大変ありがたや。
Step 5:BigQuery MCPサーバーの設定
Claude CodeからBigQueryを直接操作できるようにMCPサーバーを設定。
設定完了後は、VS CodeのClaude Codeに話しかけるだけでAIさんがBigQueryにSQLクエリを投げて結果が返ってくる。
「先週のゾーン2ランの平均心拍数を出して」
「今月の筋トレボリュームをエクササイズ別に集計して」
など。
実際のランニング後・筋トレ後の運用例
ランニング後
- Garmin Connectアプリでアクティビティのサマリーをスクリーンショットで保存
- VS CodeのClaude Codeに画像をアップロード
- 「このランニングデータをスプレッドシートに追加して、run_typeはZone2 / (メモ)」と伝える
- Claude Codeがgarmin_to_sheets.pyを実行し、スプレッドシートのrunning_logシートに追記
- 翌朝0〜1時のGAS自動実行でBigQueryに送信
スクリーンショットを撮ってClaude Codeに投げるだけ。
筋トレ後
- スプレッドシートのtraining_logシートを開く
- 日付・menu_type・種目・重量・セット・レップを入力
- 翌朝0〜1時のGAS自動実行でBigQueryに送信
筋トレは手入力。
データを修正・削除したとき
- スプレッドシートで該当行を修正または削除
- GASエディタを開き、関数「fullSyncToBigQuery」を手動実行
- BigQueryのデータがスプレッドシートと一致する
差分同期(自動)と全行洗い替え(手動)の2つで対応。
つまずいたポイントと解決策
BigQueryスキーマのJSON形式を間違えた
最初、Claudeが作成したBigQueryのスキーマJSONは配列形式[]で、エラーが出た。
ここはGeminiに聞いたほうが早いと思い、フォーマットだけGeminiに聞き、それをClaudeに伝えた。
結果、オブジェクト形式({fields: […]})で再生成。
型名でもエラーが。FLOAT64ではなくFLOAT、INT64ではなくINTEGERに修正。
Googleプロダクトに関することはGeminiに聞くのが良い(それはそう)
Anthropic APIクレジットが使えなかった
最初、課金せずに作成したAPIキーでスクリプトを動かそうとしてエラーに(えっ
課金後も同じキーを使い続けたが引き続きエラー。
原因は課金前に発行したキーがそのままだったこと?で、課金後に新しいキーを発行し直したら無事通った。
キーは課金後に作り直す、が正解?なのかな。
pace値に「/km」が含まれてしまう
Claude APIがGarmin画像から「8:05/km」という形式でペースを抽出していた。
スプレッドシートには「8:05」で入れたかったため、スクリプト側で/km以降を除去する処理を追加した。
差分同期だけでは行削除に対応できない
synced_atをキーにした差分同期は新規追加には強いが、削除・修正には弱い。
スプレッドシートで行を消してもBigQueryには残ったままになる。
全行洗い替え関数(fullSyncToBigQuery)を別途作成し、必要なときだけ手動実行する運用にした。
まとめ
トレーニングメニュー作成後、「実施結果をスプレッドシートで残し、BigQueryに取り込み、MCPサーバーで分析したい」という一言からぬるっとスタートしてしまい、そのまま1時間ほどでできた。
こんな自分でもできるのだから、生成AIはホントすごい(語彙力)
この記事も構成だけ投げて、あとは「実際今日やったことをブログ記事の体裁でそのまま書いて」とお願いして作ってもらい、そこからザクザク切ったり貼ったり変えたりして作成したので、ホントにパッと完成した。
ホントすごい時代(語彙力2回目)
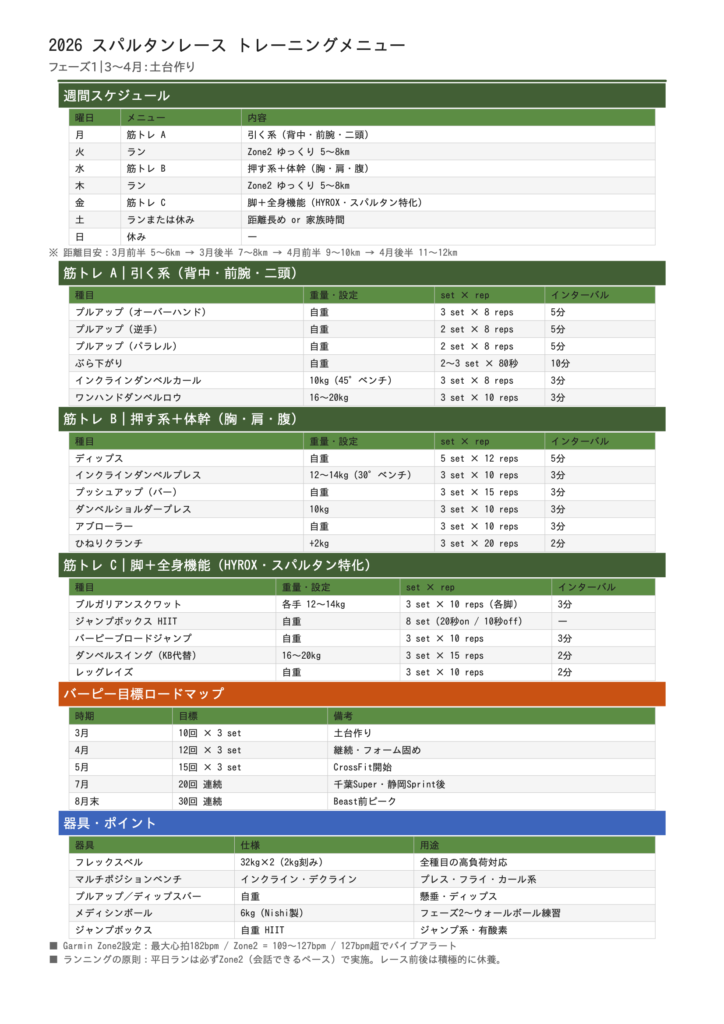
P.S. Claudeの作ってくれたトレーニングメニューはなかなかの鬼メニューだった。今後修正必至。
※これは印刷用にフェーズ1のみバージョンにしてもらったやつ。スパルタンレースのトライフェクタ達成=ゴールが9月中旬なので、フェーズ3まである。。
コメント