
日記が続かない。
これを書いている今日まで何度トライしたか覚えていないくらい、ことごとく続かなかった。
3週間が私のベスト記録だったと思います。
ということで今回、技術による解決を試みることにしました。
Notion + BigQuery + GCS でほぼ自動の日記システムを組み、コマンドを1発叩くと、その日の天気・ニュース・体重・歩数・写真までまとめて記録される仕組みにしました。
名付けて「Daybook」。
まだ動かし始めて数日。
続くかどうかは正直まだわからないけれど、設計の段階で「続かない理由」を潰す方針で組んだつもりなので、今までよりは見込みがあるはず、という話です。
追記 (2026-05-13): 公開後にいくつか改善したので、末尾に「追記」セクションを設けています。これから真似される方は本文と追記をざっと両方読んでから取りかかると、手戻りなくセットアップできます。
1. なぜ作ったか
Notion で日記を書こうとしていた時期がありました。
デイリーテンプレートを置き、毎晩そこに何か書き込むフロー。
3週間で詰まりました。
詰まった理由を後から考えると、日記そのものより周辺作業が重かった、というのが正直なところです。
スマホで撮った写真をMacに転送し、ドラッグして貼り、サイズを整え、天気を思い出して書き、体重も書こうとして HealthPlanet のアプリを開いて確認する。
本題の「今日どんな日だった」に辿り着く前に消耗していた。
逆に言うと、これら全部が自動で埋まっていれば、私が書くのは「今日どんな日だった」の1行で済む。
それなら続けられるのではないか、と。
仕様の前に、まず運用イメージから逆算しました。
夜、寝る前にコマンドを1発叩く。1〜2分で終わる。
このゴール1点だけを死守する設計で全体を組みました。
2. アーキテクチャ ― 3層構成にした理由
最初は Notion だけで完結させようとしましたが、すぐに諦めました。
Notion は閲覧体験は最高ですが、構造化データの扱いと長期保管にはあまり向きません。
逆に BigQuery は素晴らしいデータベースですが、人間が読むには向かない。
それぞれの強みを使い分ける3層構成に落ち着きました。
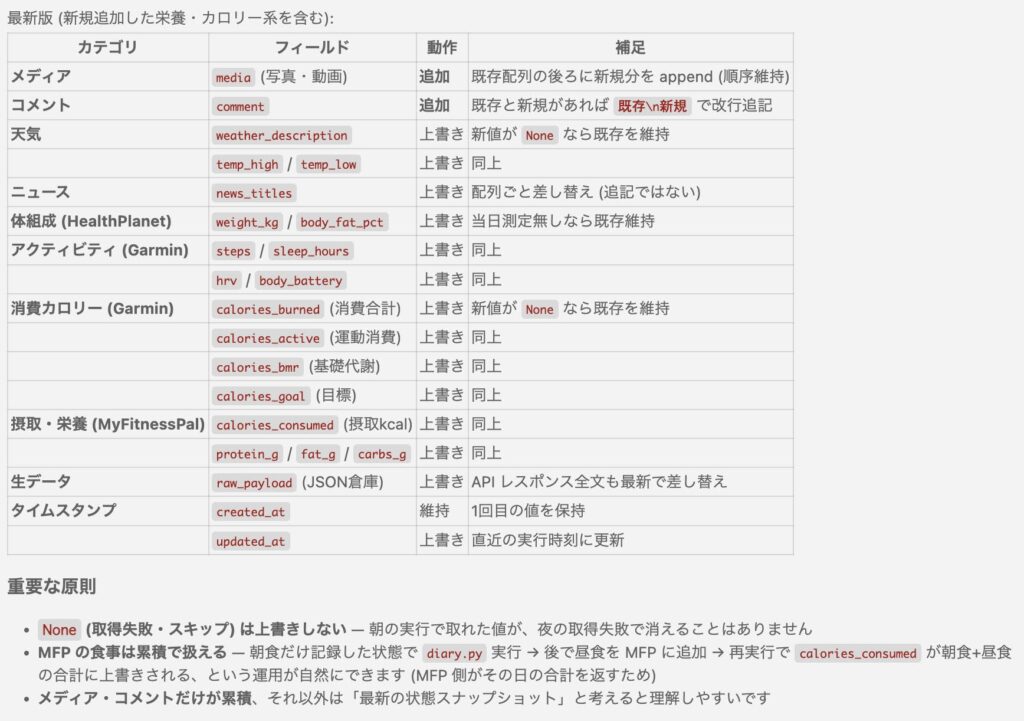
| 層 | 役割 | 中身 |
| BigQuery | 真の保存先 (source of truth) | 構造化された全データ |
| GCS (Cloud Storage) | メディア置き場 | 写真・動画・サムネイル |
| Notion | 閲覧用ビュー | カレンダーとギャラリーで振り返る |
データの流れはシンプルで、コマンドを1回叩くと、各データソースから情報が集まり、BigQuery に1行 INSERT、GCS にメディアをアップロード、Notion にページを生成する、という順で書き込まれます。Notion を消しても BigQuery から再生成できる、という関係性です。
全体像はこんな感じ。

ロケーションは BigQuery が US マルチリージョン、GCS が asia-northeast1。
BigQuery が GCS のファイル本体を読むことはなく URL 文字列だけを保持するので、跨リージョンのコストは発生しません。
GCS は家族写真も入るので国内に置いておきたかった、それだけの理由です。
3. 使うときのフロー
3-1. 日記を追加するとき
コマンドを叩くと、対話形式で進みます。
実際の画面を抜粋するとこんな感じ。
$ python diary.py
Diary entry for which date?
[1] Today (2026-05-10)
[2] Yesterday
[3] Other
> 1
How would you like to add media?
[1] Take photo with webcam
[2] Upload file(s) from PC
[3] Skip / done
[4] Pick from Google Photos
> 4
(ブラウザで Google Photos の Picker が開く → 写真を1〜数枚選択 → 完了)
Enter today’s comment:
> 朝ラン10km。久しぶりに脚が軽かった。
[weather] OpenWeatherMap から取得… 晴れ時々曇り 22.5°C / 14.1°C
[news] NHK RSS から取得… 3件
[healthplanet] 体重 66.1kg / 体脂肪 19.1%
[garmin] 歩数 12,453歩 / 睡眠 7.2h / HRV 65 / Body Battery 80
[bigquery] Saving… Done
[notion] Creating page… Done
✓ Diary saved.
私が打ち込んだのは、日付選択、メディア選択方法、コメント1行だけ。
所要1〜2分。
残りは全部勝手に集まってくれます。
3-2. 日記を削除するとき
開発中に試しで作ったテストデータを消したい、みたいな用途で使います。
# 確認 (変更なし)
$ python scripts/delete_entry.py 2026-05-08 –dry-run
# 実行
$ python scripts/delete_entry.py 2026-05-08
裏では3つのことが順に起きます。
1) GCS のメディアを削除
2) Notion ページをアーカイブ (ゴミ箱送り、復旧可能)
3) BigQuery の行を削除
順序は意図的です。
GCS と Notion は復旧手段があるので先に消し、真の保存先である BigQuery は最後。
途中で止まっても整合性が壊れにくい順序にしてあります。
4. 自動で集めるデータ
各データは独立した collector モジュールが取りに行きます。
1つ失敗しても他は止まらない、という設計にしました(雑な日もあるので)。
- 天気・気温: 当日は OpenWeatherMap、過去日は Open-Meteo Archive。OpenWeatherMap の無料プランは過去データを返してくれないので分業です
- ニュース: NHK NEWS WEB の RSS から top3。当日のみ自動、過去日は手動入力
- 体重・体脂肪率: HealthPlanet の OAuth API
- 歩数・睡眠・HRV・Body Battery: Garmin Connect (python-garminconnect)
- 写真・動画: 入力経路を4つ用意 — webcam で即時撮影、ローカルファイルのパス指定、スキップ、Google Photos Picker でブラウザから選択
5. 工夫した3つのポイント
5-1. Notion ページの「自由編集領域マーカー」
Daybook は同じ日に再実行しても1レコードに統合されるようにしてあります。朝に簡単に記録して、夜にコメントを追記する、みたいな使い方を想定しています。
ただ問題がありました。
Notion ページの本文を毎回まるごと自動生成すると、私が手書きで足したメモが上書きされて消える。
逆に上書きしないと、修正したい自動領域 (天気を取り直したいなど) が更新できない。
解決策は、ページの真ん中に目印のブロックを置くことでした。
[マーカー上: 自動生成領域]
・ 天気サマリー
・ 写真ブロック (横並び)
・ コメント
・ 健康データ
・ ニュース (折りたたみ)
✏️ ここから下は自由に編集 (Daybook再実行で消えません) ← マーカー
[マーカー下: ユーザー自由編集領域]
・ 手書きの追記、思い出メモ、なんでも
Daybook の再実行時はマーカー上だけを差し替え、マーカー下のブロックはいったん全削除 → 再投稿、という流れで保全しています。
Notion API には「ブロックの差分更新」がないので、いったん全部消して入れ直す方式に落ち着きました。
5-2. 過去日記80件の冪等な移行
実はこの Daybook を作る前、別の Notion DB (T’s Journal という名前) で日記を書こうとしていた時期があり、80件分のデータが残っていました(冒頭で「3週間で詰まった」と書きましたが、それ以外にも何度か小規模なトライをしている)。当然、これは Daybook に移行したい。
migrate_journal.py という移行スクリプトを作りました。
設計の肝は 冪等性※ (べきとうせい)です。※ある操作(演算、処理、APIリクエストなど)を1回行っても複数回行っても、システムの状態や結果が同じになる性質
BigQuery に既にその日付があれば → 全部スキップ
Notion にはあるが BQ にはない → BQ だけ追記
両方ない → 通常処理 (Notion作成 + BQ追記)
実はこの設計が後で効きました。
全件移行を走らせている途中で、開発環境のプロセスマネージャがプロセスを kill してしまい、Notion には57件作成済み、でも BigQuery には1件も入っていない、という不整合状態に陥ったことがあります。
普通なら手動で Notion を全削除してやり直すところですが、上の冪等ロジックのおかげで、もう一度 –execute を流すだけで「Notion にあるけど BQ にない57件は BQ だけ補填、残り18件は通常処理」と勝手に整理されました。所要2分9秒。
「最後まで完走することを期待しない」設計が結果的に運用の楽さに直結する、という良い学びになりました。
5-3. raw_payload で将来のスキーマ拡張に備える
BigQuery の列には「使うと決めた」項目だけ並べてあります。最高気温、最低気温、天気の説明文、体重、歩数、HRV、…。
でも各 API は実際にはもっと多くの情報を返しています。
湿度、体感温度、風速、気圧、UV指数、内臓脂肪、基礎代謝、安静時心拍数、…(返してくれるなら一応もらっておきたい)。
このまま列に出ているデータだけを保存していると、半年後に「やっぱり湿度も振り返りたい」と思ったときに困ります。
OpenWeatherMap の無料プランは過去データを返さないので、過去日付は再取得不可能。
実際 Google Photos の旧 Library API は2025年3月に廃止されました。API 仕様は変わるし、消えます。
そこで API のレスポンス全体を JSON のまま raw_payload列に保管 しておく設計にしました。
「列」と「JSON 倉庫」の二段構え。
即座に使う列: date, weather_description, temp_high, temp_low, …
取りこぼし保険: raw_payload = { weather: {OWM レスポンス全体}, … }
将来「湿度の列を追加したい」となっても、JSON_VALUE(raw_payload, ‘$.weather.response.daily[0].humidity’) のような SQL で過去レコードも自動で埋められます。再リクエスト不要。(できないこともあるので)
地味な工夫ですが、長期運用前提のシステムにはこういう保険が効くはず、と信じています。
6. Google Photos Picker API の罠
写真の取り込みで一番苦労したのがここです。
iCloud 写真は使っておらず、Google Photos に集約しているので、ここから取り込みたい。
素直に「Google Photos API」で検索すると古い記事が大量にヒットしますが、ほぼ全て使えませんでした。(古い記事の SDK サンプルが軒並み動かない)
2025年3月31日に旧 Library API のスコープが廃止 されていました。
アプリが Google Photos のライブラリ全体をスキャンしたり検索したりする機能は、もう使えません。
代替として登場したのが Photos Picker API です。
考え方が変わっています。
旧モデル: アプリが Photos の中身を直接見て、欲しい写真を取得
新モデル: アプリが「Picker セッション」を作り、ユーザーがブラウザで写真を選び、選ばれた分だけアプリに渡される
ユーザーのプライバシー保護の観点では正しい変更ですが、実装はちょっと回りくどくなりました。
フローはこう。
- アプリが POST /sessions でセッションを作る → pickerUri URL が返ってくる
- その URL をブラウザで開く (アプリは webbrowser.open() で誘導)
- ユーザーが Photos の Picker UI で写真を選び、「完了」を押す
- アプリは GET /sessions/{id} を数秒間隔でポーリングし、mediaItemsSet: true を待つ
- 完了したら GET /mediaItems で選ばれたアイテムの一覧を取得
- 各アイテムの baseUrl に =d (写真) や =dv (動画) を付けてダウンロード
- DELETE /sessions/{id} でクリーンアップ
ハマりどころは複数ありました。
OAuth 同意画面の「テストユーザー」に認可するアカウントを追加していないと access_denied で弾かれます。
Picker API の認可スコープは1つだけ (photospicker.mediaitems.readonly) でシンプル。
baseUrl に何もつけずに GET すると小さいプレビュー画像しか落ちてこない、=d をつけて初めて原寸で取れます。
新しい API の解説記事はまだ少ないので、これから取り組む人の参考になればと思って詳しめに書きました。
7. Claude Code との協働
このプロジェクトは Claude Code と一緒に作りました。
役割はだいたいこうです。
私: 何を作るか、なぜ作るか、どう運用したいか、どこを妥協してどこを譲らないか
Claude: そこから逆算した設計の選択肢、実装、テスト、ドキュメント
特に効いたのは「先にゴール (運用イメージ) で合意してから手を動かす」リズムです。
実装が走り出してから「やっぱり違う」となると手戻りが大きいので、各フェーズの最初に簡単なテキストで「やりたいこと」「やらないこと」を明文化してから進める。
これだけで後の判断がほぼ全部勝手に決まります。(これはペアプロというより設計の話ですが)
過去日記80件の移行のときに harness が処理を kill した話 (5-2) も、人間とAIのペアならではの体験でした。
私が状況に気づき、Claude が冪等ロジックの存在を思い出して「現状を確認して再実行で復旧できる」と提案、その通りに動いた。
エラー対応をリアルタイムで会話できるのは、相棒がいる感覚に近いです。
8. これから
書き始めてからまだ1日。
これからどう運用していくかは、正直やってみないと分からない部分が多いです。
ただ、「書く」というハードルを「コマンドを叩く + 1行コメント」まで下げられたのは、過去のトライと比べると一番続きそうな気がしています(楽観)。続かなかったら、続かなかった理由をまた潰す、を繰り返すだけです。
今後の野望としては、以下を順にいじっていきたいなと考えています。
- データポータル接続 (BigQuery を可視化して月次・年次で振り返る)
- iOS Shortcuts で iPhone から1タップ起動
- 月末にまとめサマリーが Slack に届く
- Whisper で音声コメント入力
ただ、機能を足すたびに「本当にいるか」を疑う癖はつけたい。
Daybook の本質は機能の多さではなく、続けられる設計にあるはずなので。
日記は仕組みで続けられる、という説をこれから検証していきます。
1ヶ月後にこの記事の続編が書けたら、それが何よりの証拠になるはず。
追記 (2026-05-13)
公開してから数日でいくつか改善したので追記します。
これから真似される方は、この追記までざっと読んでから取りかかると、初期セットアップで手戻りなく完成形に近づけます。
Notion の閲覧UIを作り込んだ
公開直後の構成は Daybook データベースに標準ビュー (テーブル / ギャラリー / カレンダー) を並べただけの状態でした。
毎日見るものとしてはちょっと情報密度が足りなかったので、Notion 側を作り込みました。
具体的には、Daybook データベースは「データの置き場」に徹してもらい、その上に閲覧専用のラッパーページ (Daybook – Front) を作る構成に変更。
ラッパーページは上下2段構成で、上段が「1行1日サマリー」のリスト (Headlines)、下段がギャラリー / カレンダー / テーブルの切替タブ、という形にしました。
ついでに Notion の Formula プロパティをいくつか追加。
- Weekday: 日付プロパティから曜日1文字 (月 火 …) を導出
- formatDate(prop(“DateProperty”), “EEE”)
- Summary: 気温・睡眠時間を1行に集約
- formatNumber(prop(“TempHigh”), “commas”, 1) + “°C / ” +
formatNumber(prop(“TempLow”), “commas”, 1) + “°C / ” +
formatNumber(prop(“SleepHours”), “commas”, 1) + “h”
formatNumber の第3引数 precision で桁数固定できることを最初知らず、長い let ネストで桁を揃える数式を書いていたのが反省点。
Notion 数式は組み込みを先に探すべき、という当たり前の学び。
食事・カロリー収支もカバーした
「これでまだ記録できていないのは食事ぐらい」というところで、MyFitnessPal (以下 MFP) と Garmin の連携で摂取・消費カロリーと PFC (タンパク質・脂質・炭水化物) を取りにいきました。
MFP は Garmin と公式に連携できているので、当初は Garmin Connect の Nutrition API 経由で MFP の食事データを取る つもりでいました。
python-garminconnect には get_nutrition_daily_food_log というそれっぽいメソッドもあります。
ところが、いざ叩いてみるとレスポンスの mealDetails が常に空。
includesCalorieConsumedData: False というフラグも返ってきます。
MFP には食事を入れているのに。
調べた結論はこう。
MFP と Garmin の連携は一方通行で、Garmin → MFP に運動データは流れるが、MFP → Garmin に食事データは流れない仕様 でした。
MFP アプリ側を見ても「Garmin Connect に栄養情報を送信」のような明示的なトグルは見当たりません。
Garmin Connect の Web 版「栄養管理」タブも、過去1年丸ごと空のグラフが表示されている状態。
連携は接続中なのに、食事データだけは絶対に Garmin 側に来ないということです。
仕方ないので MFP を直接叩く方針に切り替えました。
myfitnesspal という非公式の Python ライブラリがあり、これがそれなりにメンテされています (latest commit が約7ヶ月前、コミットは「Cloudflare 由来の 403 を修正」のような MFP 仕様変更追従が中心)。
ただ認証方式に1つ罠があって、MFP は2022年8月にログインフローに hidden captcha を導入したため、メール/パスワードでの直接ログインは不可能 になっています。
代わりに採用された方式が、ブラウザ Cookie 経由の認証。
Mac の Chrome で https://www.myfitnesspal.com/ にログインしておけば、browser_cookie3 というライブラリがその Chrome の Cookie ストアを読み取り、MFP のセッションを引き継いで API 越しにデータを取りに行ってくれる、という回りくどい仕組みです。
Safari は macOS の TCC (Transparency, Consent, and Control) で Cookie ファイルへのアクセスが封じられているため、ターミナルにフルディスクアクセスを付与しない限り使えません。
Chrome / Firefox / Brave / Edge あたりが現実的な選択肢になります。
これで取れるようになったのが:
- MFP から: 摂取カロリー / タンパク質 / 脂質 / 炭水化物 (1日の合計、食事ごとの内訳も raw_payload に保管)
- Garmin から: 消費カロリー合計 / 運動消費 / 基礎代謝 / 目標摂取
Notion ページに「🍴 カロリー・食事」セクションを足して、毎日こんな感じで自動表示されます。
🍴 カロリー・食事
・摂取目標: 1,870kcal
・摂取: 587kcal (P 38g / F 18g / C 80g)
・消費: 785kcal (運動 38 + 基礎代謝 747)
・カロリー収支: -198kcal
「ほぼ書かない日記」とは言いつつ、MFP の食事入力自体は手動でやる必要があります。
ただ MFP は10年以上前から使っている習慣なので、追加コストはほぼゼロ。
Daybook 側は MFP の入力結果を読み取って整形して並べるだけです。
副作用として「将来 iPhone から日記追加できるようにしようとした時、MFP 連携は使えるのか?」という疑問が浮かんだのですが、これは答えがあります。
MFP の Cookie 認証はあくまで Mac のブラウザ Cookie に依存しているので、iPhone から直接 Python を動かす構成では成立しません。
ただ Daybook の他の collector (Garmin / HealthPlanet) も含めて Mac で動かす前提で組まれているので、iPhone 対応は「iPhone がトリガー、Mac が実行」というモデル (Tailscale や Shortcuts 経由) になる想定です。
MFP 連携はそのモデルなら問題なく動きます。
小さい修正
- python diary.py のコメント入力で、Backspace が行頭の1文字だけ消せない macOS 特有の挙動を修正 (import readline を1行追加するだけで治る)
- メディアを2枚以上添付した時に Notion カバー画像を選び直せるよう、インタラクティブなプロンプトを追加。
Google Photos Picker API は選択結果を撮影日昇順で返してくる仕様なので、無対策だと最古の写真がカバーに固定されてしまっていた
おまけ: 全体アーキテクチャの図 (本文 2章にも反映済み)
公開時の図は3層 (BigQuery / GCS / Notion) のみのテキスト説明でしたが、collector が増えて全体像が見えにくくなってきたので、本文 2章にアーキテクチャ図を追加しました。MFP も含めた最終形です。

コメント